VeeAI
Intelligent document engine
VeeAI turns your document vault into a searchable, summarizable knowledge base. Hybrid search combines keyword precision with semantic understanding. AI summarization extracts insights from any document. A RAG pipeline powers an intelligent research assistant.
Architecture
Search and AI Architecture
VeeAI runs a dual-index search architecture. BM25 keyword search (via PostgreSQL full-text) handles exact matches. Vector search (pgvector embeddings) captures semantic similarity. Results are fused using Reciprocal Rank Fusion (RRF) for best-of-both-worlds ranking. For AI features, documents are chunked, embedded, and fed into a RAG pipeline that grounds LLM responses in your actual data.
Key Capabilities
VeeAI
Hybrid Search (BM25 + Vector)
Keyword search finds exact matches. Semantic search understands meaning. Reciprocal Rank Fusion (RRF) merges both result sets into a single ranked list. Best precision, best recall.
Map-Reduce Summarization
Long documents are split into chunks, each summarized independently (map), then combined into a coherent summary (reduce). Works on documents of any length without context window limitations.
OCR and Extraction Pipeline
Tesseract-based OCR with automatic language detection. AI-powered metadata extraction from text. Document classification and tagging. Confidence scores for quality assessment.
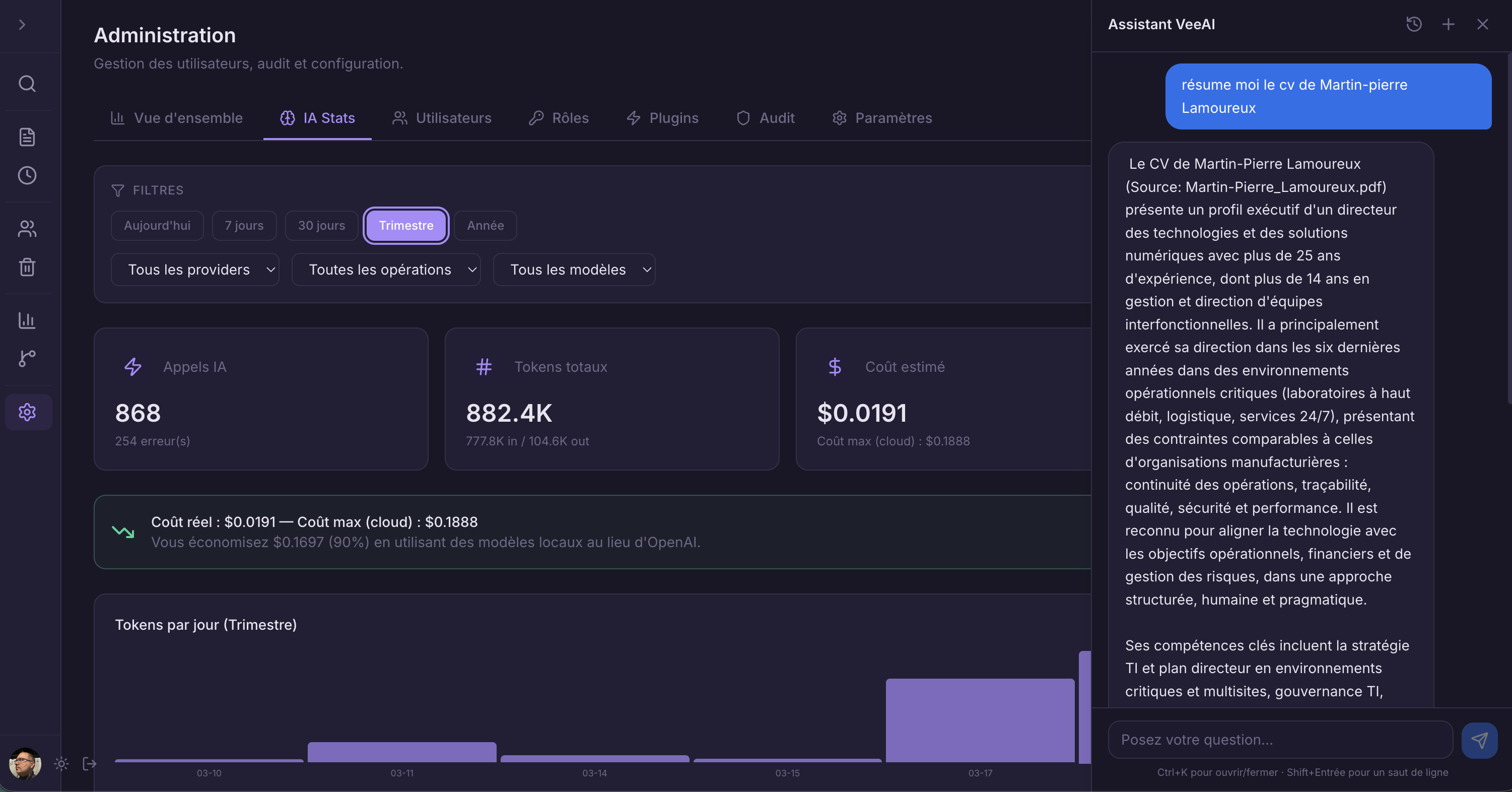
RAG Research Assistant
Retrieval-Augmented Generation pipeline. User questions are embedded, matched against document chunks via vector similarity, and fed to an LLM with source context. Answers are grounded in your actual documents.
Document Embeddings
Automatic vector embedding generation using configurable models. Chunking strategies optimized for different document types. Stored in pgvector for efficient similarity search.
Pluggable LLM Providers
Run local models via Ollama for full data sovereignty. Or connect to OpenAI, Anthropic, or any OpenAI-compatible API. Switch providers without code changes — configuration only.