VeeAI
Moteur documentaire intelligent
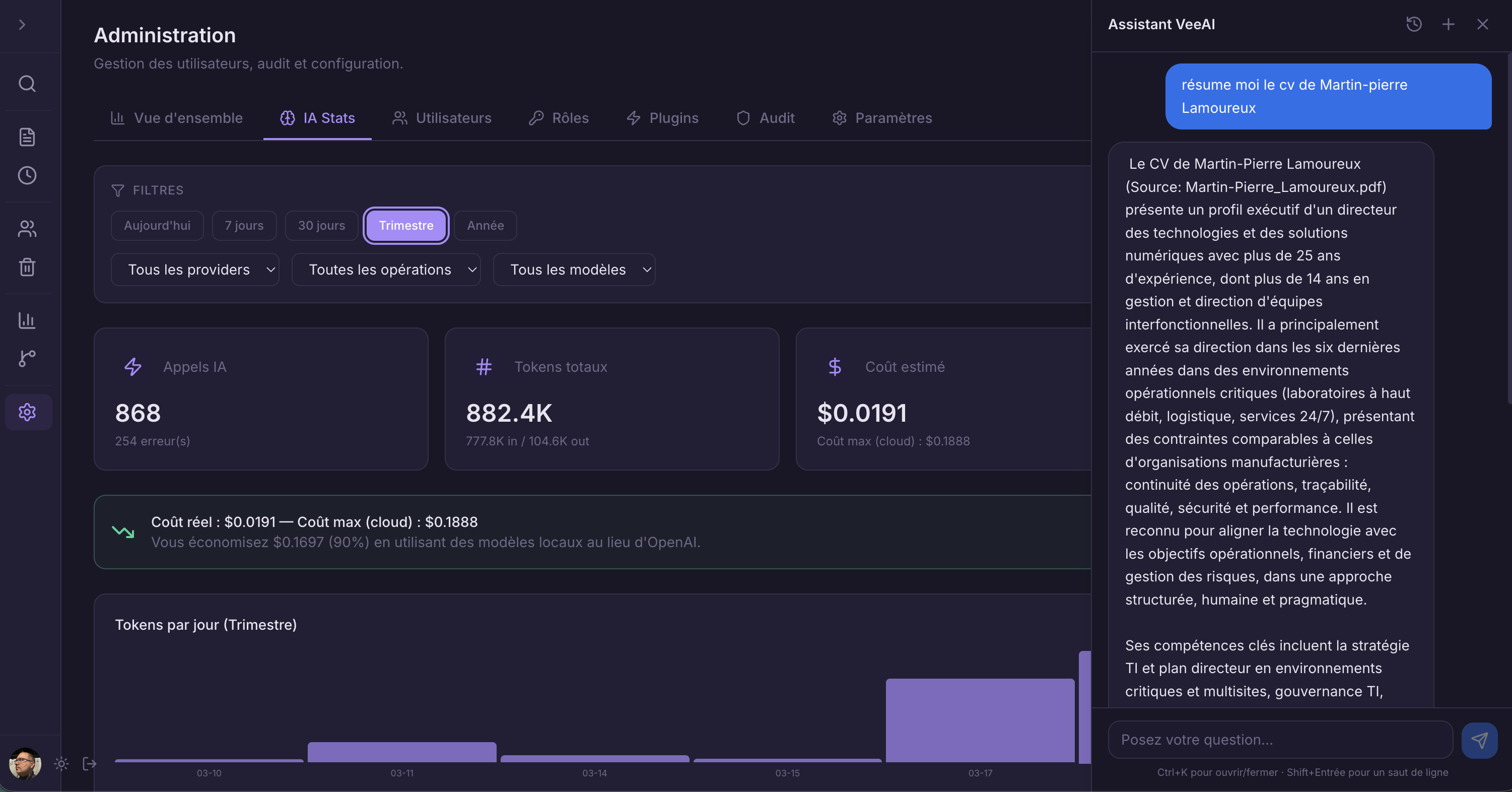
VeeAI transforme votre voûte documentaire en base de connaissances cherchable et résumable. La recherche hybride combine précision par mots-clés et compréhension sémantique. Un pipeline RAG alimente un assistant de recherche intelligent.
Architecture
Architecture recherche et IA
VeeAI exécute une architecture de recherche à double index. La recherche BM25 (via PostgreSQL full-text) gère les correspondances exactes. La recherche vectorielle (embeddings pgvector) capture la similarité sémantique. Les résultats sont fusionnés via Reciprocal Rank Fusion (RRF) pour un classement optimal. Pour les fonctionnalités IA, les documents sont découpés, vectorisés et alimentés dans un pipeline RAG qui ancre les réponses LLM dans vos données réelles.
Capacités clés
VeeAI
Recherche hybride (BM25 + Vecteur)
La recherche par mots-clés trouve les correspondances exactes. La recherche sémantique comprend le sens. Le Reciprocal Rank Fusion (RRF) fusionne les deux ensembles en un classement unique. Meilleure précision, meilleur rappel.
Synthèse Map-Reduce
Les longs documents sont découpés en chunks, chacun résumé indépendamment (map), puis combinés en un résumé cohérent (reduce). Fonctionne sur des documents de toute longueur sans limite de fenêtre de contexte.
Pipeline OCR et extraction
OCR basé sur Tesseract avec détection automatique de langue. Extraction de métadonnées par IA. Classification et étiquetage des documents. Scores de confiance pour l'évaluation de la qualité.
Assistant de recherche RAG
Pipeline de génération augmentée par récupération. Les questions sont vectorisées, comparées aux chunks par similarité, et envoyées à un LLM avec le contexte source. Les réponses sont ancrées dans vos documents réels.
Embeddings documentaires
Génération automatique d'embeddings vectoriels avec modèles configurables. Stratégies de découpage optimisées par type de document. Stockés dans pgvector pour recherche de similarité efficace.
Fournisseurs LLM interchangeables
Exécutez des modèles locaux via Ollama pour une souveraineté totale. Ou connectez OpenAI, Anthropic, ou toute API compatible OpenAI. Changez de fournisseur sans modification de code — configuration uniquement.